前の項目で、char16というベクトル型が登場しました。このベクトル型は並列処理に適しており、各ベンダーのOpenCL-C実装はハードウェア上の演算ユニットが並列で処理ができるように最適化が行なわれます。
OpenCL-Cではベクトル型を使うほうがパフォーマンスの面では有利となりますが、コードが複雑となり可読性を犠牲になってもベクトル型で記述する理由としてハードウェアリソースの最適化があります。
もちろんOpenCLにはベクトル型以外のデータ型もあり、その代表格としてスカラデータ型とイメージデータ型があります。
注記
詳しくは「表:スカラデータ型」(表B.1「表:スカラデータ型」)を参照ください。
OpenCL C言語のスカラ型は端的に言えば、複数の値でなく一つの値を持つデータ型のことです。
以下が代表的なスカラデータ型です。
- bool
- 真偽型、true/false、1/0の値をとります。
- unsigned char, uchar
- 符号なしの8ビット整数。
- short
- 符号付き2の補数の16ビット整数。
- half
- 16ビット浮動小数点。A 32-bit floating-point. IEEE 754 半精度の記憶域フォーマットに準拠。
- int
- 符号付き2の補数の32ビット整数。
- unsigned int, uint
- 符号なしの32ビット整数。
- long
- 符号付き2の補数の64ビット整数。
- float
- 32ビット浮動小数点。A 32-bit floating-point. IEEE 754 単精度の記憶域フォーマットに準拠。
- double
- 64ビット浮動小数点。A 32-bit floating-point. IEEE 754 倍精度の記憶域フォーマットに準拠。
- size_t
- 符号なしの整数型(sizeof演算子の結果として用いる)。CL_DEVICE_ADDRESS_BITSが32ビットの時は、符号なしの32ビット整数。CL_DEVICE_ADDRESS_BITSが64ビットの時は、符号なしの64ビット整数。
doubleはデバイスによってはサポートしていません。double型がデバイスでサポートされているかチェックするには、cl_khr_fp64拡張(エクステンション)がサポートされているか、clGetDeviceInfoを呼び出して情報を取得します。サポートされている場合は以下のようにして拡張を有効にします。
#pragma OPENCL EXTENSION cl_khr_fp64 : enable
もし拡張を無効とする場合は、以下のようにenableをdisableに書き換えます。
#pragma OPENCL EXTENSION cl_khr_fp64 : disable
全エクステンションを有効または無効とする場合は、個別の拡張ではなく「all」の設定をします。
#pragma OPENCL EXTENSION all : enable
注記
詳しくは「表:OpenCLホストAPIとC言語の対応表」(表B.2「表:OpenCLホストAPIとC言語の対応表」)を参照ください。
OpenCLホストアプリケーションからカーネルの引数に、データを渡す場合、ホストAPIとOpenCL-Cのデータ型は異なります。
「表:OpenCLホストAPIとC言語の対応表」(表B.2「表:OpenCLホストAPIとC言語の対応表」)に表記されている通り、bool型に対応したOpenCL APIのデータ型はありません。カーネル内でcharやintを引数として使う場合、cl_charやcl_intとして宣言したバッファオブジェクトを渡す必要があります。
基本的にOpenCLホストAPIとC言語の対応は直感的に操作することができます。記憶しなくとも慣れてくると無意識的に各データ型の対応をできるようになるものなので、無理に覚えようとしないほうがいいかもしれません。
注記
本項目は数値演算の興味の無い方はとばしてください。
スカラ型の中でも、half型は特殊ケースのため補足します。IEEE 754-2008規格という半精度浮動小数点演算の規格に準拠したデータ型でして、ここで詳細は記述しません。
IEEE 754規格は浮動小数点を(2進数)ビットで表すために以下のような計算式を示しています。
表したい浮動小数点値 = 符号 * 2^指数 * 仮数
数式とするのであれば以下のように表すことができます。

- y
- 浮動小数点値
- s
- 符号
- b
- 指数
- c
- 仮数
各要素は以下の2進数のビット数で表します。
- 符号:1ビット
- 指数:5ビット(指数バイアスは15、2^4=16のbitのみで指数部は1)
- 仮数:10ビット(正確には11bit、最上位ビットは指数部によって0から1をとる)
符号 | 指数 | 仮数 | |||||||||||||
1 | 5 | 10 | |||||||||||||
指数部は下駄履き表現とし、バイアスは15となります。
例えば、指数部分の計算をする場合、指数からバイアス(又はエキセス)を下記のように減じます。
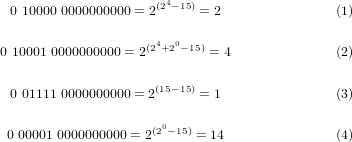
仮数部の最上位ビットは、指数部が00000の場合は0とし、それ以外(無限値となる11111を除外)を1とします。
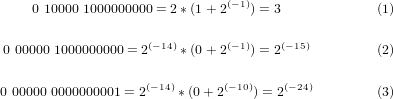
この計算のより詳細な記述を知りたい方は、IEEE754規格を参照頂くようお願い致します。
OpenCL-Cではhalf型はあまり使う機会はないかと思います。half型で計算をするハードウェアがないため、非効率な処理になる可能性が高いからです。
OpenCL 1.2以降では、half値のバッファオブジェクトを指すポインタを宣言する場合に使います。
floatは単精度浮動小数点(32bit)のスカラデータ型です。原則としてIEEE 754に準拠します。
本書を執筆している段階では、ハードウェアの演算ユニットはfloatであればサポートしているので、パフォーマンスを最適化する場合は、ハードの仕様がfloat以外をサポートしない場合は、floatをベースのデータ型としてアルゴリズムの設計を行うことを推奨します。
floatの各要素は以下の2進数のビット数で表します。
- 符号:1bit
- 指数:8bit
- 仮数:23bit
最大値は(1)、最小値は(2)で表すことができます。

符号 | 指数 | 仮数 | |||||||||||||||||||||||||||||
1 | 8 | 23 | |||||||||||||||||||||||||||||
64ビットの倍精度浮動小数点型、doubleはOpenCL規格ではオプション機能であり、多くのGPUデバイスでサポートしていません。
本書で検証機として利用しているMac Miniでdoubleがサポートされているか確認してみました。下記のように「FP_64」が定義されているか検証コードを書いてみました。
/* OpenCL 1.2では手動設定は不要 */
#ifdef FP_64
#pragma OPENCL EXTENSION cl_khr_fp64: enable
#endif
__kernel void helloworld(float f)
{
#ifdef FP_64
printf("Double precision FP supported by GPU.\n");
#else
printf("Double precision FP not supported by GPU.\n");
#endif
}実行可能ファイルの出力結果は以下のようになります。
$ ./helloworld kernel completed. Double precision FP not supported by GPU.
出力結果にあるようにMac Miniでは倍精度浮動小数点はサポートしていないことを確認できました。
double型の値は64ビット(2進数)で表します。
- 符号:1ビット
- 指数:11ビット
- 仮数:52ビット
符号 | 指数 | 仮数 |
1ビット | 11ビット | 52ビット |
doubleについては、ハードウェアでサポートされていないこともありますが、より大きなメモリ領域を確保する必要が生じるため、使える機会は限定されます。
表B.1「表:スカラデータ型」では基本的なデータ型とは別にCL_DEVICE_ADDRESS_BITSという値に依存するデータ型が存在します。以下がそのデータ型です。
- size_T
- ptrdiff_t
- intrptr_t
- uintptr_t
CL_DEVICE_ADDRESS_BITSはclGetDeviceInfo関数のparam_name引数にCL_DEVICE_ADDRESS_BITSを指定すると求めることができます。CL_DEVICE_ADDRESS_BITSの値は32か64のいずれかになります。
例えばsize_tのサイズはCL_DEVICE_ADDRESS_BITSが32の場合は、32bit、64の場合は64bitとなります。この作用は上記にあげた他3つのデータ型で共通しています。
データ型を定義する際にはハードウェアのアーキテクチャやプラットフォームについても留意する必要があります。
バイト順序と呼ばれるバイトがどのように並べられるかは0x86とIBM-Power等では異なり、以下の4つのバイト順序があります。
- リトルエンディアン(x86)
- ビッグエンディアン(IBM Power/Java Virtual Machine)
- ミドルエンディアン
- バイエンディアン(ARM)
このうち重要なものは、上2つのリトルエンディアンとビッグエンディアンです。バイエンディアンは、リトルエンディアンとビッグエンディアンを切り替え可能なアーキテクチャで、2016年時点でミドルエンディアンを採用するアーキテクチャを筆者は知らないため割愛いたします。
本書ではx86アーキテクチャを想定するため、ビッグエンディアンを使う前提ではありますが、製造したソフトウェアをパブリッシュする際には、
unsigned int x = 0x01234567;
リトルエンディアンのバイト順序は、右から左に整理されます。
67 | 45 | 23 | 01 |
というように右から左の順序に整理し、コードが左から右に記述しているバイトを逆にしています。
ビッグエンディアンはリトルエンディアンの反対の順序をとります。つまり、
01 | 23 | 45 | 67 |
という順序をとります。
バイト順序については、ベクトル型をとりあげる際にも解説します。
ベクトルはスカラ型をベースにして、charn、ucharn、shortn、intn、floatnと表記され、nは要素数に該当し、2、3、4、8、16の値を指定できます。
単なる複数の要素を持った基本データ型は配列を指すポインタでも可能ですが、ベクトル型は各要素への処理を並列化させる効用があります。
最新のプロセッサー(CPU)では、サイクル単位でデータ処理量を増やすことを目的としたIntelの実装にはSSE(Streaming SIMD extensions)やAVX(Intel Advanced Vector Extensions)といった処理方式が提供されています。
SSEは128ビット、AVXが256ビットのレジスタを持ちます。
つまり、SSEであれば4つの32ビットデータ型、AVXであれば8個の32ビットデータ型を一回のサイクルで並列で処理させることができます。
SIMD方式による命令は、レジスタの領域を効率的に使用することで、複数のベクトル要素が同時に処理されることを可能とします。
OpenCLのベクトルデータ型はこのSIMDのスレッド・スケジューリングとディスパッチを自動で行います。
そのため本の前半で紹介したMMXテクノロジのようなベンダー独自のAPIを使う必要はなく、ベクトル型への操作は、ほぼC言語で記述するのと同じ感覚でプログラミングができます。
注記
詳しくは「表:ベクトルデータ型」(表B.3「表:ベクトルデータ型」)と「表:ベクトル型の互換性」(表B.4「表:ベクトル型の互換性」)を参照ください。
IntelのGPUデバイスではメモリアドレス空間の最適化のために、最低でも32-bitのデータサイズでのアクセスが推奨されています。以下のデータ型は32ビットデータ型の例です。
- char4
- ushort2
- int
intは32ビット、char4は8 x 4、ushort2は16 x 2ということで32ビットを構成します。
重要
一般的に2の冪乗のコンポーネントを持つことがメモリ空間の最適化の原則です。
さらによりメモリを効率的に使うには以下のような4つの32-bitをまとめたベクトルデータ型が良いとされています。
- float4
- int4
これは4 x 4 = 16バイトに相当します。
最適化について追記すると、OpenCLアプリケーションでパフォーマンスをあげるには、ホストプログラム内でデータを初期化するのは定石といっていいでしょう。
その際には、本項目で解説したベクトルデータ型はOpenCL-C専用なため、ホストAPI側の対応データ型を使う必要があります。
例えば浮動小数点型、整数型のスカラデータをカーネル引数として渡すのであれば以下のようにホストプログラム内で宣言します。
- cl_float
- cl_int
ただしスカラデータ型の場合は、floatやintのままでもコンパイルは通ります。OpenCLのホストAPIの組込みデータ型が役に立つのは、ベクトルとしてデータを初期化する場合です。
OpenCL-C言語のfloatn、intnに対応するのは以下の2つです。
- cl_floatn
- cl_intn
このようにベクトル型にせよスカラ型にせよ、ホスト側とOpenCL-C(カーネル)の型の相互変換は直感的に行なうことができます。
注記
詳しくは「表:その他の組み込みデータ型」(表B.5「表:その他の組み込みデータ型」)を参照ください。
- image2d_t
- 2次元イメージ。
- image3d_t
- 3次元イメージ。
- sampler_t
- サンプラー型
- event_t
- イベント型
注記
詳しくは「表:ベクトルコンポーネント」(表B.7「表:ベクトルコンポーネント」)を参照ください。
注記
詳しくは「表:ラウンド・端数処理モード」(表B.8「表:ラウンド・端数処理モード」)を参照ください。
端数処理モードは以下の4つの種類があります。
- _rte
- 最近接偶数への丸め (round to the nearest even)
- _rtz
- 0への丸め (rounding toward zero)
- _rtp
- 正の無限大への丸め (rounding toward positive/plus infinity)
- _rtn
- 負の無限大への丸め (rounding toward negative/minus infinity)
- 修飾子を指定しない
- 既定の丸めモード、整数型は_rtz。
このモードは丸めが必要な操作をする数学関数等で指定できることがあります。
注記
詳しくは「表:整数型マクロ」(表:整数型マクロ)と「表:ホストAPIとデータ型の対応」(表B.113「表:ホストAPIとデータ型の対応」)を参照ください。