OpenCLによるヘテロジニアスデバイス環境の抽象化を理解して頂くには、OpenCL APIが何をするかを見て頂くと良いかと思います。
- ヘテロジニアス環境のプロットフォームを検出
- プラットフォーム下のハードウェアコンポーネントを検出
- コンポーネントの属性を取得
- コンポーネントで実行される命令セット(kernel)をコンパイル
- 演算に使う入力データをメモリーバッファーに変換
- 選択したプラットフォーム、コンポーネントでkernelを実行
- kernelの実行結果を取得
このようにステップバイステップで処理が進むのですが、これらのステップを大きく分類すると、以下の4つのようなモデルにまとめることができます。
- プラットフォームモデル(Platform Model)
- 実行モデル(Execution Model)
- メモリモデル(Memory Model)
- プログラミングモデル(Programming Model)
これらのモデルについては以降の項目で解説していきます。
Platform Modelはヘテロジニアスなシステム環境を上流層を記述するモデルです。これによりアーキテクチャーの異なるマイクロプロセッサーを検出しアクセスすることを可能とします。
OpenCLプラットフォームは以下の図に示されるように、マイクロプロセッサーを抽象化したものです。
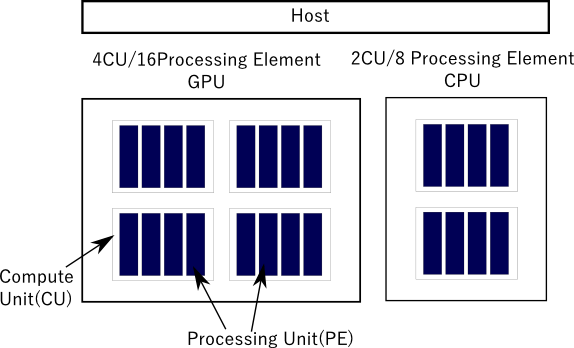
プラットフォームはホスト、デバイス(プロセッサー)、CU、PEから構成されます。CUとPEの定義は以下のようになります。
- (CU)Compute Unit: 一つ以上の演算ユニットを持つOpenCLデバイスです。ワークグループは単一演算ユニットで実行されます。Compute Unitは一つ以上の処理要素(processing elements: PE)とローカルメモリーで構成されます。
- (PE)Processing Element: 仮想スカラプロセッサです。プロセッサーに入っている最小単位(つまりスカラ型)の演算器に論理的にマップした仮想プロセッサです。
図ではGPU内に4個のCU、各CUに4個のPEで、計16個のPEがあります。CPUには2つのCU、計8個のPEがあります。Intel CPUの例でいえば、CUはコアに相当します。
Execution Modelは名前のとおり命令セットの実行を行うためのモデルです。このモデルは異種のアーキテクチャーが混在した環境のもとでの実行処理するためにあります。
実行モデルは1つのホスト(端末)に対して複数のOpenCLデバイスが存在するという前提を持ち、OpenCLデバイスでの実行プログラムを、ホストプログラムと分離させています。
ホストプログラムはホスト上で動作するもので、GPU等で動作するプログラムとは区別されます。ホストプログラムで不可欠なオブジェクトには以下のようなものがあります。
- コンテキスト
- コマンドキュー
- プログラム
- メモリオブジェクト
ヘテロジニアスな環境ではマイクロプロセッサが混在しており、ドライバも異なります。OpenCLでは実行モデルにランタイムで、カーネルと呼ばれる関数のソースコードをコンパイル・ビルドする機構を持ちます。カーネルをコンパイル・ビルドをするのはプログラムオブジェクトとなり、そこからカーネルオブジェクトを生成します。生成されたカーネルはデバイスに送られ実行処理されます。
Note
カーネルの実装例は「Section 13.7.1, “カーネル関数”」を参照ください。
ホストプログラムはOpenCLデバイスでの処理実行のためのカーネルを送るコマンドを発行します。
コマンドを発行時に、ホスト内に指定された整数のインデックス空間を生成します。カーネルのインスタンスはこのインデックス空間の各ポイントを実行します。
カーネルの各インスタンスをワークアイテムとよび、各インスタンスは整数のインデックス空間の座標で識別できます。この座標はワークアイテムのグローバルIDと呼びます。
ワークアイテムはスレッドと考えると分かりやすいかもしれません。カーネルコマンドが発行されるとワークアイテムのコレクションを生成します。インデックス空間の整数(又はグローバルID)で識別される各ワークアイテムは、同一のカーネルが指定する命令シーケンスを実行します。つまり同一のカーネルが、並列で処理され、実行中の各カーネルはグローバルIDで識別することが可能となります。
各ワークアイテムの処理内容は多くの場合に異なります。グローバルIDを入力データ配列要素のインデックスとして使用し、同じ命令シーケンスでも他のワークアイテムが持つグローバルIDが指す配列要素とはインデックスが異なる要素を処理したり、命令シーケンス内の分岐処理などによって、処理結果が各ワークアイテムで異なる形態をとらせることができます。この処理方法をSPMD(Single Program Multiple Data)と呼ぶ事があります。
Important
SPMD(Single Program Multiple Data)はカーネルがデータと所有するプログラムカウンターに対して複数の処理要素(プロセッシングエレメント、PE)を使い並行で実行されるプログラミングをさします。つまり全ての演算リソースは同一カーネルを実行しますが、自らの命令カウンタを保ちます。さらにカーネル内の分岐により、実際の命令シーケンスは各PEによって大きく異なることがあります。
ワークアイテムはワークグループに分類できます。ワークグループは整数空間を分割して、グローバルIDという単一の整数空間でなく、ワークグループIDとワークグループ内要素を識別するローカルIDの組み合わせによりワークアイテムの座標を表すことができます。
ワークグループはOpenCLでの並列処理の核心をなす概念です。これは単にグローバル空間を削減するという効果ではなく、プラットフォームモデルでご案内したデバイスの構造をフルに活用するために必須なものです。
ワークグループ内のワークアイテムは、CU(Compute Unit)内のPE(Processing Element)で並行または並列に実行することができるのです。ただしベンダーが提供するOpenCL実装ライブラリが並行・並列に処理するかは保証されていません。
Note
NDRangeの詳細・実装例については「the section called “データ並列プログラミングモデル”」、「the section called “カーネルの実行”」、「Section 13.18, “NDRange”」、「Section 13.17, “ワークグループ”」、「Section 17.4.1, “ワークアイテム関数”」を参照ください。
カーネルインスタンスのインデックス空間は、N次元の範囲(Range)として定義できます。ワークアイテムのグローバルIDとローカルIDは、N-タプルとして表すことができます。Nは1,2,3のいずれかを設定することができます。
例えばN=1の場合は、`(0)、(1)、(2)、...`といったようにインデックスは単なる整数です。
N=2の場合は、`(0,0)、(0,1)、(0,2)、...`というように2次元のインデックスで表せます。
N=3の場合は、`(0,0,0)、(0,0,1)、(0,0,2)`といったように3次元のインデックスで表せます。
ワークグループについても、同様にN-タプルで表現できます。例えば2次元のグローバルIDが(3,3)だとするとワークグループの(1,1)のローカルIDは(1,1)となります。この例は後ほど表を使って解説します。
それでは1次元のカーネルインスタンスの場合の例を見てみましょう。以下の表では、ワークアイテムの総数を8個とし、ワークグループを2つにした場合の、グローバルIDとローカルIDを列挙しています。
- W=ワークグループ数
- G=(グローバル)ワークアイテム数
- w=ワークグループID
- g=グローバルID
- l=ローカルID
ローカルIDは(0,1,2,3,0,1,2,3)となり各ワークグループの固有なIDが割り振られます。
次に2次元の例を再度見てみましょう。2次元のインデックス空間を使う場合は大抵は2次元画像の処理をすることを踏まえて、座標を(x,y)の2-タプルで表してみましょう。
以下は解説で使う変数の定義です。
- (Gx,Gy):(グローバル)ワークアイテム数
- (Wx,Wy):ワークグループ数
- (Lx,Ly):ローカルアイテム数
- (gx,gy):グローバルID
- (wx,wy):ワークグループID
- (lx,ly):ローカルID
ローカルアイテム数については以下のように、ワークアイテム数をワークグループ数で割る事をで算出できます。
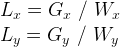
グローバルIDは、ワークグループIDとローカルアイテム数とローカルIDを合成して算出できます。
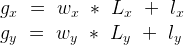
ワークグループIDと、ローカルIDの計算は以下のような数式を使います。
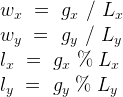
ワークグループIDの計算式は規格に沿ったものですが、少数部分を切り下げる床関数を使って整数に変換する必要があります。
最後に以下の表が、4x4の2次元インデックス空間の場合の各変数の推移となります。
Table 13.2. 図:4x4(2次元)カーネル、ワークグループ数=2
Wy | Gy | wy | gy | ly | (gx, gy) | |||
2 | 4 | 0 | 0 | 0 | (0,0) | (1,0) | (2,0) | (3,0) |
1 | 1 | (0,1) | (1,1) | (2,1) | (3,1) | |||
1 | 2 | 0 | (0,2) | (1,2) | (2,2) | (3,2) | ||
3 | 1 | (0,3) | (1,3) | (2,3) | (3,3) | |||
lx | 0 | 1 | 0 | 1 | ||||
gx | 0 | 1 | 2 | 3 | ||||
wx | 0 | 1 | ||||||
Gx | 4 | |||||||
Wx | 2 | |||||||
OpenCL実行モデルは、カーネルインスタンスの識別IDやインデックス空間の定義の他にも、OpenCLのホストプログラムのハブとなる(アクセスパタンを指定する)コンテキストを定義します。
OpenCLアプリケーションでは、コンテキストは以下の4つのリソースを使ってカーネルの実行環境を定義することに用います。
- Devices
- OpenCLデバイスのコレクション
- Kernels
- OpenCLカーネル関数(複数定義可能)
- Programオブジェクト
- カーネルを実装したプログラムソースと実行可能プログラム(カーネルを呼び出すのに用いる動的ライブラリ)
- メモリオブジェクト
- OpenCLデバイスからアクセス可能なメモリ内のオブジェクトの集合
DevicesとKernelsについては既に解説してますので、Programオブジェクトとメモリオブジェクトを見てみましょう。
Programオブジェクトはホストプログラム内でランタイムにビルド(カーネルソースコードのコンパイル)されます。これはOpenCLデバイスのターゲットが分からない状態を前提とすれば、プログラムの実行時にコンパイルして各種デバイスに対して柔軟な運用ができるメリットがあります。
Programオブジェクトのビルドをするには、ソースが必要ですが、文字列型にしてホストプログラムに置いておくか、外部ファイルをロードしてきます。
最後にコンテキスト内においてメモリを生成・初期化することができ、生成されたメモリをメモリオブジェクトと呼びます。メモリオブジェクトにはバッファオブジェクトとイメージオブジェクトの2つがあります。
ホストからデバイスへのやり取りは、コマンドキュー(command-queues)というキューに、処理したいコマンドを挿入して行ないます。
- カーネル実行コマンド
- メモリー複製・転送コマンド
- (明示的)同期コマンド
一つ目のカーネル実行コマンドはOpenCLデバイスのPE上でカーネルを実行させます。
二つ目は、コマンドキュー(command-queues)を介してデバイスにデータを転送したり、デバイスからデータを受け取る、データをマップ、アンマップするコマンドとなります。データの型式はメモリオブジェクトというOpenCLがサポートするオブジェクトに変換します。
三つ目の同期コマンドは、コマンドが処理する順序を制御するために使います。
Contextは複数のコマンドキューと関連付けることができ、各コマンドキューは独立して機能し明示的に同期をさせるメカニズムは存在しません。
キューは順序通りコマンドを実行するFIFOとできます。反面、out-of-order実行(順不同実行)を行なえるコマンドを挿入することも可能です。順不同実行では、コマンドは順序通り挿入され実行されていきますが、前のコマンドの終了を待機せずに実行をしていきます。
同一のコマンドキューでは、キューに挿入されたコマンドがイベントオブジェクトを生成することで、コマンド間の同期を行なうことができます。
Note
メモリモデルよりもメモリーモデルの方が呼びやすいのでメモリーモデルと記述します。
Memory ModelはOpenCLで使用するメモリー領域の定義であり、それらがOpenCLの演算との関連を紐付けます。Contextを解説した前の項目で軽くご紹介したメモリオブジェクトはOpenCLで使用するメモリー領域の一つです。
メモリオブジェクトにはバッファオブジェクト、イメージオブジェクトの2種類 が存在し、メモリオブジェクトは2つのクラスが継承する抽象クラスです。
原則として、ホストプログラム内のメモリ、つまりホストメモリと、メモリオブジェクトのメモリーモデルは互いに独立したメカニズムや挙動を持ちます。ですが、ホストメモリとメモリオブジェクトは相互作用を持つため、両方の関与を見るべきです。
バッファオブジェクトやイメージオブジェクト等のメモリオブジェクトは、ホストプログラム内で領域の確保を行います。
メモリオブジェクトは初期化以外でホストプログラムと関連するのは、メモリオブジェクトの内容を、ホストに複製やマッピング、アンマッピングする場合があります。またデータをホストからメモリオブジェクトに書き込むこともできるため、ホストメモリとメモリオブジェクトの読み込み・書き込みタイミング等は潜在的に問題になりえます。
メモリへのアクセスのタイミングについては、OpenCLでは2つの方式を選択できるようにしています。
- Blocking(ブロッキング)
- Non-Blocking(ノンブロッキング)
ブロッキング方式では、OpenCL関数はコマンドが処理を終えてリソースが使用可能になった段階で戻ります。ノンブロッキング方式では、コマンドが挿入された時点でOpenCL関数が戻ります。
OpenCLはメモリ整合性をプロセッサのアーキテクチャに依存してます。下記の図のように4つの種類(+ホストメモリ)のメモリが混ざりあう構成は、読者が慣れ親しんでいるであろうスタック/ヒープ/コンスタント領域で構成するC言語のメモリーモデルと比べるとやや複雑です。
OpenCLではメモリには4つの領域があり、それらは各デバイス内のメモリにマップされます。
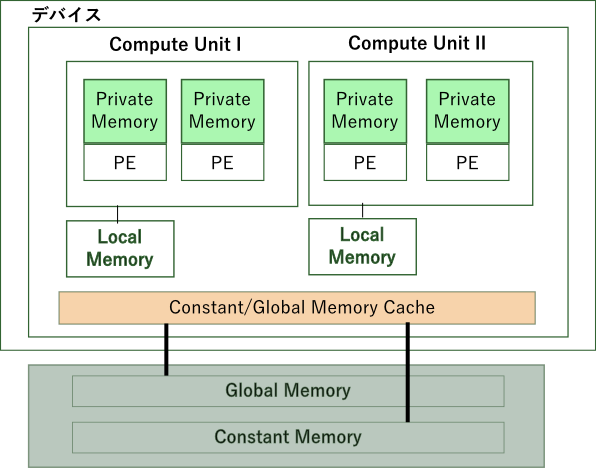
Note
この図については後の項目でも引用します。
図にある通りデバイスの中には4つのメモリ空間があります。それにホストメモリ(ホストのメインメモリ)を加えると、5つのメモリ空間が存在します。
- ホストメモリ
- ホストのみからアクセスが可能となります。OpenCLデバイス内のメモリとの相互作用を除けば、OpenCL特有の制約・機能はありません。
- グローバルメモリ
- 全てのワークグループ、ワークアイテムからの読み込み・書き込みアクセスが可能なメモリ領域です。
- コンスタントメモリ
- コンスタント領域は読み込み専用データに使い、グローバルメモリに割り当てます。(注:NVIDIA等の一部のベンダーのデバイスでは個別にキャッシュすることがあります。)書き込み処理を除いてアクセスはグローバルメモリと同じです。
- ローカルメモリ
- 一つのワークグループに局所的に割り当てられるメモリー領域です。一つのワークグループ内にある全てのワークアイテムで共有できます。
- プライベートメモリ
- 一つのワークアイテムのみが使用できるメモリ領域です。あるワークアイテムにおいてプライベートメモリ領域に変数を宣言した場合、そのメモリ領域には他のワークアイテムからアクセスはできません。
ホストメモリを除く4つはカーネル内でアクセスするメモリ領域となります。カーネル内では、原則として緩やかな整合性(異なるワークアイテムで可視化されたメモリーの中身が異なることがある。)を前提とします。では一つ一つのメモリの整合性をみてみましょう。
まずホストメモリについてはOpenCLが設ける整合性モデルはなく、C言語でいう通常のバッファなので特に言及すべきことはありません。
プライベートメモリはワークアイテムのみからアクセスが可能となっています。プライベートメモリは順序が保証されているため、ソースコードそのままの順序で処理されます。
ローカルとグローバルメモリについては、緩やかな整合性を持つため、処理順序は同期点を設けないと確保できません。この同期点はバリアーまたはその他の明示的フェンスを用いて実装できます。
Programming ModelはOpenCLでアルゴリズムを実装するための抽象モデルです。プログラミングモデルには以下の2つがあります。
- データ並列プログラミングモデル
- タスク並列プログラミングモデル
この項目ではこの2つのモデルをOpenCL APIの実装という観点から解説します。
Important
データ並列プログラミングモデルは「図:1x8(1次元)カーネル、ワークグループ数=2」(Table 13.1, “図:1x8(1次元)カーネル、ワークグループ数=2”)と「図:4x4(2次元)カーネル、ワークグループ数=2」(Table 13.2, “図:4x4(2次元)カーネル、ワークグループ数=2”)で解説したカーネルのグローバルIDの範囲を参照ください。
同一カーネルが並列に処理されるが各カーネルインスタンスは固有の命令カウンタを持つことによって、例えば2次元のイメージ画像のピクセルをx軸、y軸として識別し、各ピクセルに一つのスレッド(ワークアイテム)を割り当てます。
SPMD(Single Program Multiple Data)はカーネルがデータと所有するプログラムカウンターに対して複数の処理要素(プロセッシングエレメント、PE)を使い並行で実行されるプログラミングをさします。つまり全ての演算リソースは同一カーネルを実行しますが、自らの命令カウンタを保ちます。つまり各カーネルのインスタンス(ワークアイテム)は互いに独立しています。
Note
SPMDとカーネルインスタンスの基本動作については「the section called “カーネルの実行”」と「the section called “NDRange(N-Dimensional Range)”」を参照ください。
データ並列プログラミングモデルを実行するには、処理をさせたいカーネルをキューに挿入する必要があります。それには以下の関数を使います。
Note
詳しくは「表:clEnqueueNDRangeKernel」(Table B.88, “表:clEnqueueNDRangeKernel”)を参照ください。
pyopencl.enqueue_nd_range_kernel(
queue, #(1)
kernel, #(2)
global_work_size, #(3)
local_work_size, #(4)
global_work_offset=None, #(5)
wait_for=None, #(6)
g_times_l=False) #(7)有効なコマンドキューを指定。 | |
有効なカーネルオブジェクトを指定。 | |
要素数work_dimの配列で、カーネル関数を実行するwork_dim次元のグローバルワークアイテムの個数を指定。 | |
要素数work_dimの配列で、カーネル関数を実行する各ワークグループを構成するワークアイテムの数(ワークグループのサイズとも呼ぶ)を指定。 | |
要素数work_dimの配列でワークアイテムのグローバルIDを決定する際のオフセット値を指定。 | |
このコマンドが実行される前に完了されているイベントを指定 | |
global_work_sizeをlocal_work_sizeで乗じた値を使います。 |
Note
enqueue_nd_range_kernelについては以降の章でコード例を使いながら詳しく解説します。現時点で暗記したり記憶する必要はないので軽く流してください。
キューに挿入後にカーネルは実行されます。カーネルはOpenCL-C言語で定義・記述する関数ですが、C言語との差異はあまりありません。enqueue_nd_range_kernel関数はカーネルとホストプログラムの橋渡しをするだけではなく、データ並列プログラミングモデルをカーネルで実装するための不可欠な関数です。
タスク並列プログラミングは、C言語、C++で使うマルチスレッドと基本的には同じ意味を持ちます。
OpenCLではタスク並列の「タスク」を一つだけのワークアイテムを実行するカーネルと定義しています。
タスクを実行するには、処理をさせたいカーネルをキューに挿入する必要があります。それには以下の関数を使います。
Note
詳しくは「表:clEnqueueTask」(Table B.89, “表:clEnqueueTask”)を参照ください。
pyopencl.enqueue_task(
queue, #(1)
kernel, #(2)
wait_for=None) #(3)有効なコマンドキューを指定。カーネルはコマンドキューと関連付けられたデバイス上で実行のためにキューに入れられる。 | |
有効なカーネルオブジェクト。 | |
このコマンドが実行される前に完了されているイベントを指定 |
Note
enqueue_taskについては以降の章で詳しく解説します。現時点で暗記したり記憶する必要はないので軽く流してください。
タスク並列の「並列」については以下のような可能性があります。
- タスク内の処理単位をベクトル化して並列化(厳密にはデータ並列プログラミングとの混合)
- native kernel、つまり外部の並列処理機能を用いる
- 順不同(Out-of-Order)キューへ1個以上のタスクコマンドを挿入
いずれの方式でタスク並列プログラミングを実行するかは設計上の問題とはなりますが、NDRangeの次元1、ワークアイテム1というシンプルなタスクのプログラミングモデルなので、用途はデータ並列プログラミングモデルと比べると柔軟に選べます。