C++ 等の C 派生の言語以外で OpenCL フレームワークのバインディングを使うと、ランタイムAPI上でベクトル型の操作ができないケースが良くあります。
例えばJavaやPythonの独自ライブラリで、配列・コレクション型としてデータのバインディングがある場合には、往々にしてベクトル型への変換をカーネル内で行なう必要が出てきます。
カーネル内での「うわべだけの」(Spurious)初期化はC言語で行なう場合は、慎重に行なうべきですが、JavaでOpenCLを使うのであれば必須の操作となりえます。
ベクトルデータのloadとstoreは、vloadnとvstoren関数を使うことができます。例えば4つの要素からなる配列データをベクトルデータに移すには、vload4関数を呼び出します。
package com.book.jocl.vload;
import static org.jocl.CL.*;
import java.io.File;
import java.net.URL;
import java.nio.file.Paths;
import java.util.Scanner;
import org.jocl.Pointer;
import org.jocl.Sizeof;
import org.jocl.cl_command_queue;
import org.jocl.cl_context;
import org.jocl.cl_device_id;
import org.jocl.cl_kernel;
import org.jocl.cl_mem;
import org.jocl.cl_platform_id;
import org.jocl.cl_program;
public class LoadStoreTest {
private static final String KERNEL_PATH = "load_helloworld.cl";
private static final String FUNC = "helloworld";
private static void print_error(String src_msg, int err)
{
final String[] err_msg = new String[]{
"CL_SUCCESS",
"CL_DEVICE_NOT_FOUND",
"CL_DEVICE_NOT_AVAILABLE",
"CL_COMPILER_NOT_AVAILABLE",
"CL_MEM_OBJECT_ALLOCATION_FAILURE",
"CL_OUT_OF_RESOURCES",
"CL_OUT_OF_HOST_MEMORY",
"CL_PROFILING_INFO_NOT_AVAILABLE",
"CL_MEM_COPY_OVERLAP",
"CL_IMAGE_FORMAT_MISMATCH",
"CL_IMAGE_FORMAT_NOT_SUPPORTED",
"CL_BUILD_PROGRAM_FAILURE",
"CL_MAP_FAILURE",
"CL_MISALIGNED_SUB_BUFFER_OFFSET",
"CL_EXEC_STATUS_ERROR_FOR_EVENTS_IN_WAIT_LIST",
"CL_COMPILE_PROGRAM_FAILURE ",
"CL_LINKER_NOT_AVAILABLE",
"CL_LINK_PROGRAM_FAILURE",
"CL_DEVICE_PARTITION_FAILED",
"CL_KERNEL_ARG_INFO_NOT_AVAILABLE",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"CL_INVALID_VALUE",
"CL_INVALID_DEVICE_TYPE",
"CL_INVALID_PLATFORM",
"CL_INVALID_DEVICE",
"CL_INVALID_CONTEXT",
"CL_INVALID_QUEUE_PROPERTIES",
"CL_INVALID_COMMAND_QUEUE",
"CL_INVALID_HOST_PTR",
"CL_INVALID_MEM_OBJECT",
"CL_INVALID_IMAGE_FORMAT_DESCRIPTOR",
"CL_INVALID_IMAGE_SIZE",
"CL_INVALID_SAMPLER",
"CL_INVALID_BINARY",
"CL_INVALID_BUILD_OPTIONS",
"CL_INVALID_PROGRAM",
"CL_INVALID_PROGRAM_EXECUTABLE",
"CL_INVALID_KERNEL_NAME",
"CL_INVALID_KERNEL_DEFINITION",
"CL_INVALID_KERNEL",
"CL_INVALID_ARG_INDEX",
"CL_INVALID_ARG_VALUE",
"CL_INVALID_ARG_SIZE",
"CL_INVALID_KERNEL_ARGS",
"CL_INVALID_WORK_DIMENSION",
"CL_INVALID_WORK_GROUP_SIZE",
"CL_INVALID_WORK_ITEM_SIZE",
"CL_INVALID_GLOBAL_OFFSET",
"CL_INVALID_EVENT_WAIT_LIST",
"CL_INVALID_EVENT",
"CL_INVALID_OPERATION",
"CL_INVALID_GL_OBJECT",
"CL_INVALID_BUFFER_SIZE",
"CL_INVALID_MIP_LEVEL",
"CL_INVALID_GLOBAL_WORK_SIZE",
"CL_INVALID_PROPERTY",
"CL_INVALID_IMAGE_DESCRIPTOR",
"CL_INVALID_COMPILER_OPTIONS",
"CL_INVALID_LINKER_OPTIONS",
"CL_INVALID_DEVICE_PARTITION_COUNT",
};
int index = -err;
if (err != CL_SUCCESS) {
System.out.printf("Failed Message: %s - Error Code: %d\n", src_msg, err, err_msg[index]);
System.exit(-1);
}
}
public static void main(String[] args) throws Exception
{
int err;
/* OpenCL APIの変数 */
cl_device_id[] device = new cl_device_id[1];
cl_context context;
cl_command_queue queue;
cl_program program;
cl_platform_id[] platform = new cl_platform_id[1];
cl_kernel kernel;
/*
* OpenCLデバイスのプラットフォームの特定
* 最初に見つけたプラットフォームを使用します。
* */
err = clGetPlatformIDs(1, platform, null);
/*
* CPU/GPUデバイスの情報取得をします。
* */
err = clGetDeviceIDs(platform[0], CL_DEVICE_TYPE_GPU, 1, device, null);
if(err == CL_DEVICE_NOT_FOUND) {
err = clGetDeviceIDs(platform[0], CL_DEVICE_TYPE_CPU, 1, device, null);
}
/* コンテキストの生成をします。 */
context = clCreateContext(null, 1, device, null, null, null);
/*
* OpenCL Cのソースコードをファイル(.cl)から
* 読み込みコンパイルします
* */
/* ファイルを読み込みバッファーに投入します */
StringBuffer sb = new StringBuffer();
URL resource = LoadStoreTest.class.getResource(KERNEL_PATH);
String path = Paths.get(resource.toURI()).toFile().getAbsolutePath();
System.out.println(path);
Scanner sc = new Scanner(new File(path));
while(sc.hasNext()) {
sb.append(sc.nextLine() + "\n");
}
/* programの生成(ファイルからOpenCL Cソースコードの読み込み) */
int[] errPtr = new int[1];
program = clCreateProgramWithSource(context,
1, new String[]{sb.toString()}, null, errPtr);
if(errPtr[0] < 0) {
print_error("clCreateProgramWithSource",errPtr[0]);
}
/* programのビルド(コンパイル)をします。 */
err = clBuildProgram(program, 0, null, null, null, null);
if(err < 0) {
print_error("clBuildProgram",err);
}
/* コマンドキューを生成します */
queue = clCreateCommandQueue(context, device[0], 0, null);
/* Kernelを生成します */
kernel = clCreateKernel(program, FUNC, null);
float[] array = new float[64];
for(int i = 0; i < 64; i++) {
array[i] = (float) i;
}
cl_mem g_array = clCreateBuffer(
context,
CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR,
Sizeof.cl_float*64,
Pointer.to(array),
null);
err = 0;
err |= clSetKernelArg(kernel, 0, Sizeof.cl_float4*16, null);
err |= clSetKernelArg(kernel, 1, Sizeof.cl_mem, Pointer.to(g_array));
/*
* Kernelの実行をします。
* */
err = clEnqueueTask(queue, kernel, 0, null, null);
// Wait for the commands to complete before reading back results
if(err < 0) {
print_error("clEnqueueTask",err);
};
clFinish(queue);
/* OpenCL APIで割り当てたメモリーを解放します */
clReleaseMemObject(g_array);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseCommandQueue(queue);
clReleaseContext(context);
}
}load_helloworld.cl.
__kernel void helloworld(
__local float4* foo, //(1)
__global float* bar) //(2)
{
*foo = vload4(0, bar); //(3)
*(foo+1) = vload4(0, bar + 4); //(4)
printf("-----after vload4-----\n");
printf("%#v4f\n", *foo);
printf("%#v4f\n", *(foo+1));
printf("-----before vstore4-----\n");
printf("%f\n", *(bar+4));
printf("%f\n", *(bar+5));
printf("-----after vstore4-----\n");
__global float4* g_data;
*g_data = (float4) (1.0f, 2.0f, 3.0f, 4.0f);
__global float *data;
vstore4(*g_data, 0, bar); //(5)
printf("%f\n", *(bar+3));
printf("%f\n", *(bar+4));]
ローカルメモリ領域に記憶する引数foo | |
グローバルメモリ領域に記憶する引数bar | |
vload4を使ってbarからfooにデータを複製 | |
(bar+4)から(foo+1)にデータを複製(括弧の中はポインタ演算) | |
barにg_dataを上書きします。 |
出力.
status: 1 Well aligned. kernel completed. -----vload4----- 0.000000,1.000000,2.000000,3.000000 4.000000,5.000000,6.000000,7.000000 -----before vstore4----- 4.000000 5.000000 -----after vstore4----- 4.000000 4.000000
注記
詳しくは「表:ロードと保存」(表B.118「表:ロードと保存」)を参照ください。
vloadn関数はアラインメントのとれてないベクトルのロードに使います。
gentypen vloadn(
size_t offset,
const global gentype *p)sizeof(gentypen)バイトのデータ(p + (offset * n)のアドレスで読み込み)を返します。
gentypeがcharまたはucharのときは、(p + (offset * n))として計算されるアドレスは8-bitとして揃う(アラインメントをとる)必要があります。
gentypeがshortまたはushortのときは、16-bit長で揃えます。int、uint、floatのときは、32-bit長で揃えます。long、ulong、doubleのときは、64-bit長で揃えます。
vstoren関数はアラインメントのとれてないベクトルの書き込みに使います。
void vstoren(
gentypen data,
size_t offset,
global gentype *p)sizeof(gentypen)のデータを(p + (offset * n))のアドレスに書き込みます。
gentypeがcharまたはucharのときは、(p + (offset * n))として計算されるアドレスは8-bitとして揃う(アラインメントをとる)必要があります。
gentypeがshortまたはushortのときは、16-bit長で揃えます。int、uint、floatのときは、32-bit長で揃えます。long、ulong、doubleのときは、64-bit長で揃えます。
vload_halfnはアラインメントのとれてないベクトルのロードをし、floatのベクトルを返します。
floatn vload_halfn(
size_t offset,
const global half *p)sizeof(halfn)バイトのデータ(p + (offset * n)のアドレスで読み込み)を返します。
読み込んだデータはhalfnとして解釈されます。そしてhalfnの値はfloatnに変換され、floatnの値が返されます。(p + (offset * n)のアドレスは、16-bit長で揃える必要があります。
注記
詳細は「表:同期関数」(表B.119「表:同期関数」)を参照ください。
カーネル内で同期点を持つには、barrier関数を使います。カーネルを実行する*ワークグループ内のワークアイテム*は、その他の全てのワークアイテムがバリアーを超えた処理(バリアー関数の後に記述された処理)に進むために、この関数を実行する必要があります。この関数はカーネルを実行する全てのワークアイテムによって呼び出されます。
以下が関数の定義です。
void barrier (
cl_mem_fence_flags flags
)flagsは以下2つの値を取ります。
- CLK_LOCAL_MEM_FENCE
- 関数はローカルメモリーの変数をフラッシュするか、メモリーフェンスをキューにいれて、ローカルメモリー領域においてメモリ操作の順序性を確保します。
- CLK_GLOBAL_MEM_FENCE
- メモリーフェンスをキューにいれて、グローバルメモリー領域においてメモリ操作の順序性を確保します。例えばワークアイテムがバッファーやイメージに書き込みして、更新したデータを読み込む際に使うことができます。
重要
barrierはワークグループ内のワークアイテムの同期を行ないますが、ワークグループ間の同期は行ないません。
メモリ操作の順序性はメモリーフェンスを使うため、mem_fence関数のメモリへのコミットの順序の属性を持ちます。
barrierはメモリの整合性と操作の同期を同時に達成します。ただしbarrierをループや分岐処理内で使うことは、ハング(デッドロックに類似した現状)によるクラッシュを発生させるので注意が必要です。ハングは以下の状況で発生します。
- ワークグループの一部のスレッドが戻らない。そのためbarrierが待機し続ける。(ワークアイテムの一つもbarrierに到達しない場合は、逆に問題にならない。)
__kernel void helloworld(__global uint* g_mat,
__local uint* l_mat)
{
size_t gid = get_global_id(0);
size_t lid = get_local_id(0);
size_t group = get_group_id(0);
size_t lsize = get_local_size(0);
size_t wgsize= get_num_groups(0);
__global uint* output;
//printf("g_mat[%d] = %u\n", group * lsize + lid, *(g_mat+gid));
uint sum = 0;
for(int i = 1; i <= 1000; i++) {
sum += group;
}
l_mat[lid] = sum;
barrier(CLK_LOCAL_MEM_FENCE);
//printf("l_mat[%u] = %u\n", lid, l_mat[lid]);
if(lid == 0) {
uint group_sum = 0;
for(size_t i = 0; i < lsize; i++) {
group_sum += l_mat[i];
}
g_mat[group] = group_sum;
//printf("output[%u] = %u\n", gid, g_mat[group]);
}
barrier(CLK_GLOBAL_MEM_FENCE);
if(group == 0){
uint output_sum = 0;
for(size_t i = 0; i < wgsize; i++) {
output_sum += g_mat[i];
}
g_mat[wgsize] = output_sum;
//printf("output_sum = %u\n", output_sum);
}
}注記
詳細は「表:メモリフェンス関数」(表B.120「表:メモリフェンス関数」)を参照ください。
*ワークアイテム内でメモリの整合性を取りたい場合*にはmem_fence関数を使い読み込み、書き込みのタイミング・順序を整列させます。
以下が関数の定義です。
void mem_fence (
cl_mem_fence_flags flags
)この関数はカーネルを実行するワークアイテムのロードや保存の前後の順序を整列させます。これはメモリーフェンスの後に記述されたロードや保存が行われる前に、ロードや保存はメモリーにコミットされることを意味します。
重要
同じワークグループ内のワークアイテムが全て終了することを保証するbarrier関数に対して、mem_fenceはメモリの(load/store)整合性を保証します。つまりワークアイテム内でmem_fenceの以前に起きたload/storeはメモリにコミットされ、その後にロードが行なわれます。ただしbarrier関数はmem_fenceを呼び出すため、ワークグループ内の同期と整合性が保証されます。
この他にも、読み込み・書き込みだけに限定したフェンスを設けることができる以下の関数があります。
void read_mem_fence (
cl_mem_fence_flags flags)
void write_mem_fence (
cl_mem_fence_flags flags)flags引数についてはbarrier関数と同様に、CLK_LOCAL_MEM_FENCE CLK_GLOBAL_MEM_FENCEの2つの値を指定できます。
__kernel void helloworld(__global uint* g_mat1,
__global uint* g_mat2)
{
size_t id = get_global_id(0);
g_mat2[a] = g_mat1[id];
mem_fence(CLK_LOCAL_MEM_FENCE);
g_mat2[b] = g_mat1[id+1];
}明示的メモリフェンスとは、g_mat2のインデックスaのstore、g_mat1のインデックスidのloadの処理がメモリにコミットされた後に、g_mat2のインデックスbへのstoreとg_mat1のインデックスid+1のloadが処理されることを保証します。
注記
当たり前のように感じられるかもしれませんが、フェンスを明示することによってコンパイラに順序があるということを知らせることができます。
注記
詳細は「表:非同期ワークグループ関数」(表B.121「表:非同期ワークグループ関数」)を参照ください。
非同期複製の関数には2つの機能があります。
- ローカルメモリの中身をグローバルメモリに複製
- グローバルメモリの中身をローカルメモリに複製
これは以下の関数プロトタイプの引数をグローバル変数をローカル変数に変えるだけで使いわけられます。
event_t async_work_group_copy (
__local gentype *dst, //(1)
const __global gentype *src, //(2)
size_t num_gentypes, //(3)
event_t event) //(4)コピー先に確保されたメモリ領域を指すポインタ | |
コピー元のメモリーのアドレスを指すポインタ | |
コピーする要素数、ワークグループ内のワークアイテム数と同じ | |
他のイベントと関連付けるイベントオブジェクト、0の場合は何もしない。 |
__kernel void helloworld(__global uint* g_mat, __local uint* l_mat, uint num_rows, uint num_cols)
{
size_t gid = get_global_id(0);
size_t lid = get_local_id(0);
size_t group = get_group_id(0);
size_t lsize = get_local_size(0);
printf("g_mat[%d] = %u\n", group * lsize + lid, *(g_mat+gid)); //(1)
event_t my_evt;
my_evt = async_work_group_copy(
l_mat, //(2)
g_mat + (group * lsize), //(3)
4, //(4)
(event_t) 0
);
wait_group_events(1, &my_evt); //(5)
g_mat[lsize * lid + group] = l_mat[lid]; //(6)
}配列の中身を順に標準出力におくります。 | |
コピー先のローカルメモリ領域を指すポインタ | |
コピー元のグローバルメモリのアドレスを指すポインタ | |
コピーするサイズ(ローカルワークサイズと同じ) | |
my_evtの終了を待ちます。 | |
行列の転置をします。行順の要素を列順に入れかえる。 |
g_mat[8] = 8 g_mat[9] = 9 g_mat[10] = 10 g_mat[11] = 11 g_mat[12] = 12 g_mat[0] = 0 g_mat[13] = 13 g_mat[1] = 1 g_mat[14] = 14 g_mat[2] = 2 g_mat[15] = 15 g_mat[3] = 3 g_mat[4] = 4 g_mat[5] = 5 g_mat[6] = 6 g_mat[7] = 7 0 //(1) 4 8 12 1 //(2) 5 9 13 2 //(3) 6 10 14 3 //(4) 7 11 15
注記
詳しくは「表:アトミック関数」(表B.122「表:アトミック関数」)を参照ください。
barrier関数はワークグループ内のスレッドの同期をとるため、「ローカルな同期」を行ないます。
アトミック関数は主に競合アクセスが発生するデータに対する「グローバルまたはローカル」なメモリ整合性を確保するために使います。
ごく一部の例外を除いて、int型、unsigned int型のみで提供されています。
おそらく一番分かりやすいアトミック関数は、atomic_addです。まずグローバルメモリへ加算をする種類を見てみましょう。
int atomic_add (
volatile __global int *p,
int val)ポインタpが指すアドレスで32-bitの値(oldと呼称)を読みこみ、次に(old + val)を計算し、結果をpが指すアドレスに書き込みます。
関数はoldを返します。
次に変数をアトミックにインクリメントする関数です。
int atomic_inc (
volatile __global int *p)この関数はポインタpが指すアドレスで32-bitの値(oldと呼称)を読みこみ、次に(old + 1)を計算し、結果をpが指すアドレスに書き込みます。関数はoldを返します。
次にローカルメモリの整合性をとる種類をみてみましょう。
int atomic_add (
volatile __local int *p,
int val)基本的にはグローバルメモリのものと一緒なのですが、アトミック関数を使う場合には、ローカルメモリの初期化にbarrier関数を使うことが必要な場合があります。
もちろんグローバルメモリでも順序性が必要な場合であればbarrierと組み合わせることができます。グローバル変数と同様に、類似したatomic_incも用意されています。
浮動小数点数でアトミックなスワップ操作を行なう関数もあります。
float atomic_xchg (
volatile __global float *p,
float val)この関数はアドレスpに保存された古い値を、引数で指定した値valとスワップし、古い値を返します。
この関数はint型でもサポートされています。
注記
詳しくは「表:シャッフル関数」(表B.123「表:シャッフル関数」)を参照ください。
定義.
gentypen shuffle (
gentypem x,
ugentypen mask)
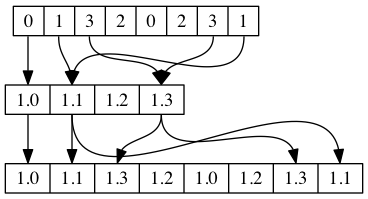
shuffle関数は一つの入力ベクトルに対してマスクを適用し、要素間の順序変更をします。shuffleではマスク要素は ilogb(2m-1) 数の最下位ビットのみを使います。
定義.
gentypen shuffle2 (
gentypem x,
gentypem y,
ugentypen mask)
shuffle2関数は2つの入力ベクトルに対してマスクを適用し、要素間の順序変更をします。shuffle2ではマスク要素は ilogb(2m-1)+1 のみを使います。
__kernel void helloworld(
__global uint* g_mat)
{
float4 in1 = (float4)(1.5f, 15.0f,5.0f,7.5f);
float4 in2 = (float4)(-20.0f, -5.0f, 1.0f, 100.0f);
uint4 shuffle_mask = (uint4)(0,3,2,1);
uint8 shuffle2_mask = (uint8)(0,3,2,1,5,4,7,6);
float4 result1 = shuffle(in1, shuffle_mask);
printf("Shuffle Result vector is %#2.1v4f\n", result1);
float8 result2 = shuffle2(in1, in2, shuffle2_mask);
printf("Shuffle2 Result vector is %#2.1v8f\n", result2);
}Shuffle Result vector is 1.5,7.5,5.0,15.0 Shuffle2 Result vector is 1.5,7.5,5.0,15.0,-5.0,-20.0,100.0,1.0