Note
kernel_rearrangeはシーケンシャルな処理のため、CPUに行わせるほうが処理速度はあがります。
GPUでの基数整列の実装については、既に解説しており極力忠実にコードに落としていきます。
この実装では、4つの整数を要素にもつ配列を整列するため、ベクトル型であるuint4の配列に元データを記憶します。
ただしuint4にした場合、アルゴリズムが右側の要素(列)から左に一つ一つ走査する場合は、動的に要素にアクセスしなくてはなりません。そのため要素アクセスのための関数、get_elementが必要となります。
inline uint get_element(uint4 data, int idx, __constant uint4* mask) {
uint result;
uint4 mask_data = data & mask[idx];
result = mask_data.s0 + mask_data.s1 + mask_data.s2 + mask_data.s3;
return result;
}このインライン関数は32bitのmaskと、指定した添字の変数idxを元に、ベクトルから該当する値を抽出します。
このget_elementを使って元データのdata変数の値を取り出して、ヒストグラムを計算するのがaccumulatorカーネル関数です。
__kernel void accumulator(
__global const uint4* data,
uint index,
__constant uint4* mask,
__local uint* shmem,
__global uint* results)
{
size_t gid = get_global_id(0);
uint pos = get_element(data[gid],index,mask);
atomic_inc(&results[pos]);
}この関数はアトミック関数を使い、results配列にたいしてヒストグラムを更新する最も単純なヒストグラムの算出をします。
up_sweepカーネル関数は既出ですが以下の擬似コードに沿って実装します。
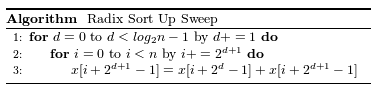
このアルゴリズムの反復部分は全てホスト側でおこなっているため、デバイス側(カーネル関数)では、xの更新のみを行います。
up_sweepカーネル関数.
__kernel void up_sweep(
__global uint* count,
uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << (stage)) >> 1;
uint right_stride = left_stride << 1;
count[offset+right_stride-1] = count[offset+left_stride-1] + count[offset+right_stride-1];
}
down_sweepカーネル関数は既出ですが以下の擬似コードに沿って実装します。
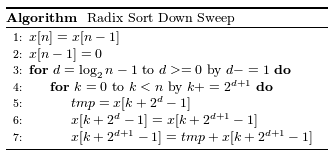
up-sweepと同様にループの箇所はホスト側でまわしているため、ループの中の更新箇所(tmpとx)の計算を行います。
__kernel void down_sweep(
__global uint* count,
const uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << stage) >> 1;
uint right_stride = left_stride << 1;
uchar tmp = count[offset+left_stride-1];
count[offset+left_stride-1] = count[offset+right_stride-1];
count[offset+right_stride-1] = tmp + count[offset+right_stride-1];
}配列の並び替えは単純にシーケンシャルな計算をします。CPU実装例と同じなので確認してみてください。この実装例ではGPUで処理をさせていますが、CPUのほうが高速で処理できます。
rearrangeカーネル関数.
__kernel void rearrange(
__global uint4* data,
__global uint* count,
uint index,
__constant uint4* mask,
__global uint4* result)
{
for(int i = 0; i < SIZE; i++) {
uint pos = get_element(data[i],index,mask);
result[count[pos]++] = data[i];
}
}
LSDSortGPU.py.
import pyopencl as cl
import numpy as np
from numpy.random import *
KERNEL_LSD_HISTOGRAM = "accumulator"
KERNEL_LSD_UP = "up_sweep"
KERNEL_LSD_DOWN = "down_sweep"
KERNEL_LSD_REARRANGE = "rearrange"
BIN_SIZE = 4
WORDS = 4
DATA_SIZE = 32
masks = np.array([[0xffffffff, 0, 0, 0],
[0, 0xffffffff, 0, 0],
[0, 0, 0xffffffff, 0],
[0, 0, 0, 0xffffffff]]).astype(np.uint32)
raw_data = randint(0, BIN_SIZE, DATA_SIZE * WORDS).astype(np.uint32)
data = raw_data.reshape((DATA_SIZE, WORDS))
print(data)
raw_tmp = np.zeros(DATA_SIZE * WORDS).astype(np.uint32)
result = raw_tmp.reshape((DATA_SIZE, WORDS))
devices = [cl.get_platforms()[0].get_devices(cl.device_type.GPU)[0]]
ctx = cl.Context(devices)
queue = cl.CommandQueue(ctx)
mf = cl.mem_flags
data_mem = cl.Buffer(ctx, mf.USE_HOST_PTR, hostbuf=data)
mask_mem = cl.Buffer(ctx, mf.USE_HOST_PTR, hostbuf=masks)
opt_string = "-DSIZE="+str(DATA_SIZE)
options = [opt_string]
program = cl.Program(ctx, """
inline uint get_element(uint4 data, int idx, __constant uint4* mask) {
uint result;
uint4 mask_data = data & mask[idx];
result = mask_data.s0 + mask_data.s1 + mask_data.s2 + mask_data.s3;
return result;
}
__kernel void down_sweep(
__global uint* count,
const uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << stage) >> 1;
uint right_stride = left_stride << 1;
uchar tmp = count[offset+left_stride-1];
count[offset+left_stride-1] = count[offset+right_stride-1];
count[offset+right_stride-1] = tmp + count[offset+right_stride-1];
printf("DOWN gid: %d, count[%d] = %d, count[%d]: %d\\n",gid,offset+right_stride-1,count[offset+right_stride-1],offset+left_stride-1,count[offset+left_stride-1]);
}
__kernel void up_sweep(
__global uint* count,
uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << (stage)) >> 1;
uint right_stride = left_stride << 1;
count[offset+right_stride-1] = count[offset+left_stride-1] + count[offset+right_stride-1];
printf("UP gid: %d, count[%d]: %d, count[%d]: %d\\n",gid,offset+right_stride-1,count[offset+right_stride-1],offset+left_stride-1,count[offset+left_stride-1]);
}
__kernel void rearrange(
__global uint4* data,
__global uint* count,
//__global uint* idx,
uint index,
__constant uint4* mask,
__global uint4* result)
{
for(int i = 0; i < SIZE; i++) {
uint pos = get_element(data[i],index,mask);
result[count[pos]++] = data[i];
}
}
__kernel void accumulator(
__global const uint4* data,
uint index,
__constant uint4* mask,
__local uint* shmem,
__global uint* results)
{
size_t gid = get_global_id(0);
uint pos = get_element(data[gid],index,mask);
atomic_inc(&results[pos]);
}
""").build(options=options)
kernel_histogram = cl.Kernel(program, name=KERNEL_LSD_HISTOGRAM)
kernel_up = cl.Kernel(program, name=KERNEL_LSD_UP)
kernel_down = cl.Kernel(program, name=KERNEL_LSD_DOWN)
kernel_rearrange = cl.Kernel(program, name=KERNEL_LSD_REARRANGE)
mf = cl.mem_flags
for w in reversed(range(WORDS)):
out_mem = cl.Buffer(ctx, mf.READ_WRITE | mf.USE_HOST_PTR, hostbuf=result)
count_mem = cl.Buffer(ctx, mf.READ_WRITE | mf.USE_HOST_PTR, hostbuf=np.zeros(BIN_SIZE+1).astype(np.uint32))
kernel_histogram.set_arg(0, data_mem)
kernel_histogram.set_arg(1, np.uint32(w))
kernel_histogram.set_arg(2, mask_mem)
kernel_histogram.set_arg(3, cl.LocalMemory(BIN_SIZE))
kernel_histogram.set_arg(4, count_mem)
cl.enqueue_nd_range_kernel(
queue=queue,
kernel=kernel_histogram,
global_work_size=(DATA_SIZE,),
local_work_size=(1, ))
ns = np.uint32(np.log2(BIN_SIZE))
tmp = np.zeros(BIN_SIZE+1).astype(np.uint32)
cl.enqueue_read_buffer(queue, mem=count_mem, hostbuf=tmp)
print(tmp)
for stage in range(ns):
gws = np.uint32(BIN_SIZE / (2 << stage))
if gws > 0:
kernel_up.set_arg(0, count_mem)
kernel_up.set_arg(1, np.uint32(stage))
cl.enqueue_nd_range_kernel(
queue=queue,
kernel=kernel_up,
global_work_size=(gws,),
local_work_size=(1,))
queue.flush()
count = np.zeros(BIN_SIZE+1).astype(np.uint32)
cl.enqueue_read_buffer(queue=queue, mem=count_mem, hostbuf=count)
count[BIN_SIZE] = count[BIN_SIZE-1]
count[BIN_SIZE-1] = 0;
cl.enqueue_write_buffer(queue, mem=count_mem, hostbuf=count)
for d in reversed(range(0, ns)):
gws = np.uint32((BIN_SIZE / (2 << d)))
if gws > 0:
kernel_down.set_arg(0, count_mem)
kernel_down.set_arg(1, np.uint32(d))
cl.enqueue_nd_range_kernel(queue, kernel_down, global_work_size=(gws,), local_work_size=(1,))
queue.flush()
kernel_rearrange.set_arg(0, data_mem)
kernel_rearrange.set_arg(1, count_mem)
kernel_rearrange.set_arg(2, np.uint32(w))
kernel_rearrange.set_arg(3, mask_mem)
kernel_rearrange.set_arg(4, out_mem)
cl.enqueue_task(queue=queue, kernel=kernel_rearrange)
queue.flush()
cl.enqueue_copy_buffer(queue, src=out_mem, dst=data_mem)
out_mem.release()
count_mem.release()
queue.flush()
cl.enqueue_read_buffer(queue, mem=data_mem, hostbuf=data)
print(data)