GPUでの基数整列の実装については、既に解説しており極力忠実にコードに落としていきます。
この実装では、4つの整数を要素にもつ配列を整列するため、ベクトル型であるuint4の配列に元データを記憶します。
ただしuint4にした場合、アルゴリズムが右側の要素(列)から左に一つ一つ走査する場合は、動的に要素にアクセスしなくてはなりません。そのため要素アクセスのためのget_element関数(下記)が必要となります。
inline uint get_element(uint4 data, int idx, __constant uint4* mask) {
uint result;
uint4 mask_data = data & mask[idx];
result = mask_data.s0 + mask_data.s1 + mask_data.s2 + mask_data.s3;
return result;
}このインライン関数は32bitのmaskと、指定した添字の変数idxを元に、ベクトルから該当する値を抽出します。
このget_elementを使って元データのdata変数の値を取り出して、ヒストグラムを計算するのがaccumulatorカーネル関数です。
__kernel void accumulator(
__global const uint4* data,
uint index,
__constant uint4* mask,
__local uint* shmem,
__global uint* results)
{
size_t gid = get_global_id(0);
uint pos = get_element(data[gid],index,mask);
atomic_inc(&results[pos]);
}この関数はアトミック関数を使ってresults配列にたいして単純にインクリメントをします。
up_sweepカーネル関数は既出ですが以下の擬似コードに沿って実装します。
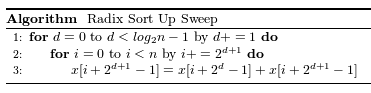
このアルゴリズムの反復部分は全てホスト側でおこなっているため、デバイス側(カーネル関数)では、xの更新のみを行います。
up_sweepカーネル関数.
__kernel void up_sweep(
__global uint* count,
uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << (stage)) >> 1;
uint right_stride = left_stride << 1;
count[offset+right_stride-1] = count[offset+left_stride-1] + count[offset+right_stride-1];
}
down_sweepカーネル関数は既出ですが以下の擬似コードに沿って実装します。
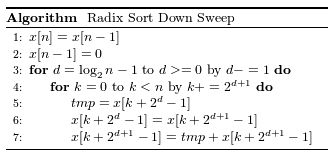
up-sweepと同様にループの箇所はホスト側でまわしているため、ループの中の更新箇所(tmpとx)の計算を行います。
__kernel void down_sweep(
__global uint* count,
const uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << stage) >> 1;
uint right_stride = left_stride << 1;
uchar tmp = count[offset+left_stride-1];
count[offset+left_stride-1] = count[offset+right_stride-1];
count[offset+right_stride-1] = tmp + count[offset+right_stride-1];
}配列の並び替えは単純にシーケンシャルな計算をします。CPU実装例と同じなので確認してみてください。この実装例ではGPUで処理をさせていますが、CPUのほうが高速で処理できます。
rearrangeカーネル関数.
__kernel void rearrange(
__global uint4* data,
__global uint* count,
uint index,
__constant uint4* mask,
__global uint4* result)
{
for(int i = 0; i < SIZE; i++) {
uint pos = get_element(data[i],index,mask);
result[count[pos]++] = data[i];
}
}
LSDSortGPU.java.
package com.book.jocl.reduction;
import static org.jocl.CL.*;
import java.io.File;
import java.net.URL;
import java.nio.file.Paths;
import java.util.Scanner;
import org.jocl.CL;
import org.jocl.Pointer;
import org.jocl.Sizeof;
import org.jocl.cl_command_queue;
import org.jocl.cl_context;
import org.jocl.cl_context_properties;
import org.jocl.cl_device_id;
import org.jocl.cl_kernel;
import org.jocl.cl_mem;
import org.jocl.cl_platform_id;
import org.jocl.cl_program;
public class LSDSortGPU {
private static final String KERNEL_LSD_HISTOGRAM = "accumulator";
private static final String KERNEL_LSD_PATH = "lsd.cl";
private static final String KERNEL_LSD_UP = "up_sweep";
private static final String KERNEL_LSD_DOWN = "down_sweep";
private static final String KERNEL_LSD_REARRANGE = "rearrange";
private static final int BIN_SIZE = 32;
private static final int WORDS = 4;
private static final int DATA_SIZE = 16; // 4-vector conversion... 256*128*8=262144
private static int[] data = new int[DATA_SIZE*WORDS];
private static final int[] masks = new int[] {
0xffffffff, 0, 0, 0,
0, 0xffffffff, 0, 0,
0, 0, 0xffffffff, 0,
0, 0, 0, 0xffffffff
};
private static cl_context context;
private static cl_command_queue queue;
private static cl_program program;
private static cl_kernel kernel_histogram;
private static cl_kernel kernel_up;
private static cl_kernel kernel_down;
private static cl_kernel kernel_rearrange;
public static void main(String[] args) throws Exception {
CL.setExceptionsEnabled(true);
cl_platform_id[] platform = new cl_platform_id[1];
cl_device_id[] device = new cl_device_id[1];
int[] num_devices = new int[1];
clGetPlatformIDs(1, platform, null);
clGetDeviceIDs(platform[0], CL_DEVICE_TYPE_GPU, 1, device, num_devices);
cl_context_properties props = new cl_context_properties();
props.addProperty(CL_CONTEXT_PLATFORM, platform[0]);
context = clCreateContext(props, 1, device, null, null, null);
queue = clCreateCommandQueue(context, device[0], 0, null);
StringBuffer sb = new StringBuffer();
URL resource = LSDSortGPU.class.getResource(KERNEL_LSD_PATH) ;
String path = Paths.get(resource.toURI()).toFile().getAbsolutePath();
Scanner sc = new Scanner(new File(path));
while(sc.hasNext()) {
sb.append(sc.nextLine() + "\n");
}
sc.close();
program = clCreateProgramWithSource(context, 1, new String[] {sb.toString()}, null, null);
String option = "-Werror -DSIZE=";
StringBuffer opbuf = new StringBuffer();
opbuf.append(option);
opbuf.append(DATA_SIZE);
clBuildProgram(program, 0, null, opbuf.toString(), null, null);
cl_mem mask_mem = clCreateBuffer(context,
CL_MEM_READ_ONLY|CL_MEM_USE_HOST_PTR,
Sizeof.cl_uint4*4,
Pointer.to(masks), null);
kernel_histogram = clCreateKernel(program, KERNEL_LSD_HISTOGRAM, null);
kernel_up = clCreateKernel(program, KERNEL_LSD_UP, null);
kernel_down = clCreateKernel(program, KERNEL_LSD_DOWN, null);
kernel_rearrange = clCreateKernel(program, KERNEL_LSD_REARRANGE, null);
generateSample();
int[] result = new int[DATA_SIZE*WORDS];
cl_mem data_mem = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR,
Sizeof.cl_uint4 * DATA_SIZE, Pointer.to(data), null);
for(int w = WORDS-1; w >= 0; w--) {
System.out.println(w);
cl_mem out_mem = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR,
Sizeof.cl_uint4* DATA_SIZE, Pointer.to(result), null);
cl_mem count_mem = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR,
Sizeof.cl_uint*(BIN_SIZE+1), null, null);
clSetKernelArg(kernel_histogram, 0, Sizeof.cl_mem, Pointer.to(data_mem));
clSetKernelArg(kernel_histogram, 1, Sizeof.cl_uint, Pointer.to(new int[]{w}));
clSetKernelArg(kernel_histogram, 2, Sizeof.cl_mem, Pointer.to(mask_mem));
clSetKernelArg(kernel_histogram, 3, Sizeof.cl_uint *BIN_SIZE, null);
clSetKernelArg(kernel_histogram, 4, Sizeof.cl_mem, Pointer.to(count_mem));
long[] gws_histogram = new long[]{DATA_SIZE,1,1};
long[] lws_histogram = new long[]{1,1,1};
clEnqueueNDRangeKernel(queue, kernel_histogram, 1, null,
gws_histogram,
lws_histogram,
0, null, null);
int ns = log2(BIN_SIZE);
long gws = 0;
for(int stage=0; stage < ns; stage++) {
gws = (long) (BIN_SIZE / (2 << (stage)));
//System.out.println(gws+" "+d);
if( gws > 0) {
clSetKernelArg(kernel_up, 0, Sizeof.cl_mem, Pointer.to(count_mem));
clSetKernelArg(kernel_up, 1, Sizeof.cl_uint, Pointer.to(new int[]{stage}) );
clEnqueueNDRangeKernel(queue, kernel_up, 1, null,
new long[]{gws},
new long[]{1},
0, null, null);
}
}
int[] count = new int[BIN_SIZE+1];
clEnqueueReadBuffer(queue, count_mem, CL_TRUE, 0,
Sizeof.cl_uint*(BIN_SIZE+1), Pointer.to(count), 0, null, null);
for(int s = 0; s < BIN_SIZE+1; s++)
System.out.println("UP: "+count[s]);
count[BIN_SIZE] = count[BIN_SIZE-1];
count[BIN_SIZE-1] = 0;
clEnqueueWriteBuffer(queue, count_mem, CL_TRUE, 0,
Sizeof.cl_uint*(BIN_SIZE+1), Pointer.to(count), 0, null, null);
for(int d=ns-1; d >= 0; d--) {
gws = (long) (BIN_SIZE / (2 << (d)));
//System.out.println(gws+" "+d);
if( gws > 0) {
clSetKernelArg(kernel_down, 0, Sizeof.cl_mem, Pointer.to(count_mem));
clSetKernelArg(kernel_down, 1, Sizeof.cl_uint, Pointer.to(new int[]{d}) );
clEnqueueNDRangeKernel(
queue,
kernel_down, 1, null,
new long[]{gws},
new long[]{1},
0, null, null);
}
}
clSetKernelArg(kernel_rearrange, 0, Sizeof.cl_mem, Pointer.to(data_mem));
clSetKernelArg(kernel_rearrange, 1, Sizeof.cl_mem, Pointer.to(count_mem));
clSetKernelArg(kernel_rearrange, 2, Sizeof.cl_uint, Pointer.to(new int[]{w}));
clSetKernelArg(kernel_rearrange, 3, Sizeof.cl_mem, Pointer.to(mask_mem));
clSetKernelArg(kernel_rearrange, 4, Sizeof.cl_mem, Pointer.to(out_mem) );
clEnqueueTask(queue, kernel_rearrange, 0, null, null);
clEnqueueCopyBuffer(queue,
out_mem,
data_mem, 0, 0,
Sizeof.cl_mem, 0, null, null);
clEnqueueReadBuffer(queue, out_mem, CL_TRUE, 0,
Sizeof.cl_uint*DATA_SIZE*WORDS, Pointer.to(data), 0, null, null);
for(int l = 0; l < DATA_SIZE*WORDS; l+=4) {
System.out.println("OUT: "+data[l]+data[l+1]+data[l+2]+data[l+3]);
}
clReleaseMemObject(out_mem);
clReleaseMemObject(count_mem);
}
int[] a = new int[WORDS*DATA_SIZE];
clEnqueueReadBuffer(queue, data_mem,
CL_TRUE, 0,
Sizeof.cl_uint*DATA_SIZE*WORDS,
Pointer.to(a), 0, null, null);
clFinish(queue);
for(int l = 0; l < DATA_SIZE*WORDS; l+=WORDS) {
System.out.println("FINAL OUT: "+a[l]+a[l+1]+a[l+2]+a[l+3]);
}
}
private static void generateSample() {
int[] tmp = new int[] {
1,4,5,0,
1,2,2,0,
1,3,2,1,
1,3,2,4,
1,3,2,6,
7,2,1,0,
1,4,5,3,
1,2,1,0,
2,4,5,0,
2,2,2,0,
2,3,2,1,
2,3,2,4,
7,3,2,6,
7,2,1,0,
7,4,5,3,
1,2,1,0
};
data = tmp;
}
private static int log2(int b) {
int result = 0;
if((b & 0xffff0000) != 0) {
b >>>= 16;
result = 16;
}
if(b >= 256) {
b >>>= 8;
result += 8;
}
if(b >= 16) {
b >>>= 4;
result += 4;
}
if(b >= 4) {
b >>>= 2;
result += 2;
}
return result + (b >>> 1);
}
}
lsd.cl.
inline uint get_element(uint4 data, int idx, __constant uint4* mask) {
uint result;
uint4 mask_data = data & mask[idx];
result = mask_data.s0 + mask_data.s1 + mask_data.s2 + mask_data.s3;
return result;
}
__kernel void down_sweep(
__global uint* count,
const uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << stage) >> 1;
uint right_stride = left_stride << 1;
uchar tmp = count[offset+left_stride-1];
count[offset+left_stride-1] = count[offset+right_stride-1];
count[offset+right_stride-1] = tmp + count[offset+right_stride-1];
printf("DOWN gid: %d, count[%d] = %d, count[%d]: %d\n",gid,offset+right_stride-1,count[offset+right_stride-1],offset+left_stride-1,count[offset+left_stride-1]);
}
__kernel void up_sweep(
__global uint* count,
uint stage)
{
uint gid = get_global_id(0);
uint offset = gid * (2 << (stage));
uint left_stride = (2 << (stage)) >> 1;
uint right_stride = left_stride << 1;
count[offset+right_stride-1] = count[offset+left_stride-1] + count[offset+right_stride-1];
printf("UP gid: %d, count[%d]: %d, count[%d]: %d\n",gid,offset+right_stride-1,count[offset+right_stride-1],offset+left_stride-1,count[offset+left_stride-1]);
}
__kernel void rearrange(
__global uint4* data,
__global uint* count,
//__global uint* idx,
uint index,
__constant uint4* mask,
__global uint4* result)
{
for(int i = 0; i < SIZE; i++) {
uint pos = get_element(data[i],index,mask);
result[count[pos]++] = data[i];
}
//printf("pos=%d, gid=%d, data=%v4d\n",pos, gid, data[gid]);
}
__kernel void accumulator(
__global const uint4* data,
uint index,
__constant uint4* mask,
__local uint* shmem,
__global uint* results)
{
size_t gid = get_global_id(0);
uint pos = get_element(data[gid],index,mask);
atomic_inc(&results[pos]);
}
出力.
FINAL OUT: 1210 FINAL OUT: 1210 FINAL OUT: 1220 FINAL OUT: 1321 FINAL OUT: 1324 FINAL OUT: 1326 FINAL OUT: 1450 FINAL OUT: 1453 FINAL OUT: 2220 FINAL OUT: 2321 FINAL OUT: 2324 FINAL OUT: 2450 FINAL OUT: 7210 FINAL OUT: 7210 FINAL OUT: 7326 FINAL OUT: 7453
警告
この項目ではCPUとGPUの連携をします。APUやiGPUとCPUが想定される実行環境であり、外部GPUデバイスとCPUのシステム構成で実装するとパフォーマンスを低下させる可能性があるので注意してください。
本書で提示した基数整列の実装アルゴリズムのうち並び替え(Rank)部分はシーケンシャルな処理をしています。そのためシーケンシャルな処理が得意なCPUで処理をするほうが効率的となります。
マルチキュー実装では、一つのコンテキストに複数のコマンドキュー を作り、カーネルの実行時にコマンドキューを使い分けます。各コマンドキューにはCPU、GPU等の処理デバイスを指定します。これにより、カーネルコマンドをキューに挿入する際に、どのキューにいれるかを指定するかによってデバイスを切り替えることが可能となります。
package com.book.jocl.reduction;
import static org.jocl.CL.*;
import java.io.File;
import java.net.URL;
import java.nio.file.Paths;
import java.util.Scanner;
import org.jocl.CL;
import org.jocl.Pointer;
import org.jocl.Sizeof;
import org.jocl.cl_command_queue;
import org.jocl.cl_context;
import org.jocl.cl_context_properties;
import org.jocl.cl_device_id;
import org.jocl.cl_kernel;
import org.jocl.cl_mem;
import org.jocl.cl_platform_id;
import org.jocl.cl_program;
public class LSDSortGPUCPU {
private static final String KERNEL_LSD_PATH = "lsd.cl";
private static final String KERNEL_LSD_HISTOGRAM = "accumulator";
private static final String KERNEL_LSD_UP = "up_sweep";
private static final String KERNEL_LSD_DOWN = "down_sweep";
private static final String KERNEL_LSD_REARRANGE = "rearrange";
private static final int BIN_SIZE = 32;
private static final int WORDS = 4;
private static final int DATA_SIZE = 16;
private static int[] data = new int[DATA_SIZE*WORDS];
private static final int[] masks = new int[] {
0xffffffff, 0, 0, 0,
0, 0xffffffff, 0, 0,
0, 0, 0xffffffff, 0,
0, 0, 0, 0xffffffff
};
private static cl_context context;
private static cl_command_queue gpu_queue;
private static cl_command_queue cpu_queue;
private static cl_program program;
private static cl_kernel kernel_histogram;
private static cl_kernel kernel_up;
private static cl_kernel kernel_down;
private static cl_kernel kernel_rearrange;
public static void main(String[] args) throws Exception {
CL.setExceptionsEnabled(true);
cl_platform_id[] platform = new cl_platform_id[1];
cl_device_id[] gpu_device = new cl_device_id[1];
cl_device_id[] cpu_device = new cl_device_id[1];
int[] num_devices = new int[1];
clGetPlatformIDs(1, platform, null);
clGetDeviceIDs(platform[0], CL_DEVICE_TYPE_GPU, 1, gpu_device, num_devices); //(1)
clGetDeviceIDs(platform[0], CL_DEVICE_TYPE_CPU, 1, cpu_device, num_devices); //(2)
cl_device_id[] devices = new cl_device_id[] {gpu_device[0] , cpu_device[0]}; //(3)
cl_context_properties props = new cl_context_properties();
props.addProperty(CL_CONTEXT_PLATFORM, platform[0]);
context = clCreateContext(props, 2, devices, null, null, null); //(4)
gpu_queue = clCreateCommandQueue(context, devices[0], 0, null); //(5)
cpu_queue = clCreateCommandQueue(context, devices[1], 0, null); //(6)
StringBuffer sb = new StringBuffer();
URL resource = LSDSortGPUCPU.class.getResource(KERNEL_LSD_PATH) ;
String path = Paths.get(resource.toURI()).toFile().getAbsolutePath();
Scanner sc = new Scanner(new File(path));
while(sc.hasNext()) {
sb.append(sc.nextLine() + "\n");
}
sc.close();
program = clCreateProgramWithSource(context, 1, new String[] {sb.toString()}, null, null);
String option = "-Werror -DSIZE=";
StringBuffer opbuf = new StringBuffer();
opbuf.append(option);
opbuf.append(DATA_SIZE);
clBuildProgram(program, 2, devices, opbuf.toString(), null, null); //(7)
cl_mem mask_mem = clCreateBuffer(context,
CL_MEM_READ_ONLY|CL_MEM_USE_HOST_PTR,
Sizeof.cl_uint4*4,
Pointer.to(masks), null);
kernel_histogram = clCreateKernel(program, KERNEL_LSD_HISTOGRAM, null);
kernel_up = clCreateKernel(program, KERNEL_LSD_UP, null);
kernel_down = clCreateKernel(program, KERNEL_LSD_DOWN, null);
kernel_rearrange = clCreateKernel(program, KERNEL_LSD_REARRANGE, null);
generateSample();
int[] result = new int[DATA_SIZE*WORDS];
cl_mem data_mem = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR,
Sizeof.cl_uint4 * DATA_SIZE, Pointer.to(data), null);
for(int w = WORDS-1; w >= 0; w--) {
cl_mem out_mem = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR,
Sizeof.cl_uint4* DATA_SIZE, Pointer.to(result), null);
cl_mem count_mem = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR,
Sizeof.cl_uint*(BIN_SIZE+1), null, null);
clSetKernelArg(kernel_histogram, 0, Sizeof.cl_mem, Pointer.to(data_mem));
clSetKernelArg(kernel_histogram, 1, Sizeof.cl_uint, Pointer.to(new int[]{w}));
clSetKernelArg(kernel_histogram, 2, Sizeof.cl_mem, Pointer.to(mask_mem));
clSetKernelArg(kernel_histogram, 3, Sizeof.cl_uint *BIN_SIZE, null);
clSetKernelArg(kernel_histogram, 4, Sizeof.cl_mem, Pointer.to(count_mem));
clEnqueueNDRangeKernel(gpu_queue, kernel_histogram, 1, null,
new long[]{DATA_SIZE},
new long[]{1},
0, null, null);
int ns = log2(BIN_SIZE);
long gws = 0;
for(int stage=0; stage < ns; stage++) {
gws = (long) (BIN_SIZE / (2 << (stage)));
if( gws > 0) {
clSetKernelArg(kernel_up, 0, Sizeof.cl_mem, Pointer.to(count_mem));
clSetKernelArg(kernel_up, 1, Sizeof.cl_uint, Pointer.to(new int[]{stage}) );
clEnqueueNDRangeKernel(gpu_queue, kernel_up, 1, null,
new long[]{gws},
new long[]{1},
0, null, null);
}
}
int[] count = new int[BIN_SIZE+1];
clEnqueueReadBuffer(gpu_queue, count_mem, CL_TRUE, 0,
Sizeof.cl_uint*(BIN_SIZE+1),
Pointer.to(count), 0, null, null);
for(int s = 0; s < BIN_SIZE+1; s++)
System.out.println("UP: "+count[s]);
count[BIN_SIZE] = count[BIN_SIZE-1];
count[BIN_SIZE-1] = 0;
clEnqueueWriteBuffer(gpu_queue, count_mem, CL_TRUE, 0,
Sizeof.cl_uint*(BIN_SIZE+1),
Pointer.to(count), 0, null, null);
for(int d=ns-1; d >= 0; d--) {
gws = (long) (BIN_SIZE / (2 << (d)));
if( gws > 0) {
clSetKernelArg(kernel_down, 0, Sizeof.cl_mem, Pointer.to(count_mem));
clSetKernelArg(kernel_down, 1, Sizeof.cl_uint, Pointer.to(new int[]{d}) );
clEnqueueNDRangeKernel(
gpu_queue,
kernel_down, 1, null,
new long[]{gws},
new long[]{1},
0, null, null);
}
}
clFlush(gpu_queue); //(8)
clSetKernelArg(kernel_rearrange, 0, Sizeof.cl_mem, Pointer.to(data_mem));
clSetKernelArg(kernel_rearrange, 1, Sizeof.cl_mem, Pointer.to(count_mem));
clSetKernelArg(kernel_rearrange, 2, Sizeof.cl_uint, Pointer.to(new int[]{w}));
clSetKernelArg(kernel_rearrange, 3, Sizeof.cl_mem, Pointer.to(mask_mem));
clSetKernelArg(kernel_rearrange, 4, Sizeof.cl_mem, Pointer.to(out_mem) );
clEnqueueTask(cpu_queue, kernel_rearrange, 0, null, null); //(9)
clFlush(cpu_queue); //(10)
clEnqueueCopyBuffer(gpu_queue,
out_mem,
data_mem, 0, 0,
Sizeof.cl_mem, 0, null, null);
clEnqueueReadBuffer(gpu_queue, out_mem, CL_TRUE, 0,
Sizeof.cl_uint*DATA_SIZE*WORDS, Pointer.to(data), 0, null, null);
for(int l = 0; l < DATA_SIZE*WORDS; l+=4) {
System.out.println("OUT: "+data[l]+data[l+1]+data[l+2]+data[l+3]);
}
clReleaseMemObject(out_mem);
clReleaseMemObject(count_mem);
}
int[] a = new int[WORDS*DATA_SIZE];
clEnqueueReadBuffer(gpu_queue, data_mem,
CL_TRUE, 0,
Sizeof.cl_uint*DATA_SIZE*WORDS,
Pointer.to(a), 0, null, null);
clFinish(gpu_queue);
clFinish(cpu_queue);
for(int l = 0; l < DATA_SIZE*WORDS; l+=WORDS) {
System.out.println("FINAL OUT: "+a[l]+a[l+1]+a[l+2]+a[l+3]);
}
}
private static void generateSample() {
data = new int[] {
1,4,5,0,
1,2,2,0,
1,3,2,1,
1,3,2,4,
1,3,2,6,
7,2,1,0,
1,4,5,3,
1,2,1,0,
2,4,5,0,
2,2,2,0,
2,3,2,1,
2,3,2,4,
7,3,2,6,
7,2,1,0,
7,4,5,3,
1,2,1,0
};
}
private static int log2(int b) {
int result = 0;
if((b & 0xffff0000) != 0) {
b >>>= 16;
result = 16;
}
if(b >= 256) {
b >>>= 8;
result += 8;
}
if(b >= 16) {
b >>>= 4;
result += 4;
}
if(b >= 4) {
b >>>= 2;
result += 2;
}
return result + (b >>> 1);
}
}
CPUのデバイスオブジェクトを生成します。 | |
GPUのデバイスオブジェクトを生成します。 | |
GPUとCPUのデバイスオブジェクトを配列として宣言します。 | |
CPUとGPUデバイスからなるコンテキストを生成します。 | |
GPUデバイスのコマンドキューを生成します。 | |
CPUデバイスのコマンドキューを生成します。 | |
GPUキューをフラッシュします。これによりCPUキュー実行開始のためにリソースを解放します。シリアルな処理をする場合はclFinishやイベントを使います。 | |
CPUキューにコマンドを挿入します。 | |
CPUキューをフラッシュします。シリアルな処理をする場合はclFinishやイベントを使います。 |