OpenCLをサポートするデバイスには2つの構成物があります。
- Compute Unit(CU)
- Processing Element(PE)
Compute Unitの中にProcessing Elementという処理単位があるので、1つのCUに対して複数のPEが存在することになります。PEは仮想スカラプロセッサであり、デバイスの各パーツにマップされます。
Compute Unitについては各ベンダーで異なる仕様・形態として定義されています。
- Execution Unit(Intel)
- Streaming MultiProcessor(NVIDIA)
- Compute Unit(AMD)
後で追記しますが、PEが処理する単位をOpenCLではワークアイテムと呼びます。1個のワークアイテムは1スレッドに相当します。1個のCUが処理する単位はワークグループと呼びます。
ワークグループには複数のCUの境界を超えた処理ができない制約があります。例えばCU1とCU2にワークグループ1を割り当てることはできません。反対にワークグループを実際にあるCUの数よりも多く作ることはできます。
ワークグループとワークアイテムは、CUとPEの概念と類似しているので読者が困惑するかもしれませんが、わかやすく区別する方法があります。ワークグループとワークアイテムは論理的な処理単位でアプリケーションが一時的に生成するもので、CUとPEは物理的に存在するデバイス内の集積回路コンポーネントを抽象化(ないし仮想化)した処理単位と考えることです。
例えば、ワークグループとワークアイテムは物理的に存在するCUやPEよりも多く割り当てることができます。ワークグループやワークアイテムはソフトウェア上のメモリ領域に存在するもので、コンパイラが各CUやPEにスケジューリング・最適化を行なって、物理層のCUとPEに対してマッピングを行ないます。
CUとPEは図を見て直感的に把握可能かもしれませんが、OpenCLフレームワークで開発する場合、ワークグループ、ワークアイテムとのマッピングはOpenCL実装ライブラリが行なうため間接的な制御までしかできません。ワークアイテムの定義に追記すると、一つ以上のPE上で実行処理を行なうことができます。
前項の説明ではPEについて全くイメージが湧かないと思います。しかしPEの具体像をもつより、むしろPEの完全な理解は不要と切り捨てるべきと筆者は考えています。
例えば、NVIDIAのMaxwell-2アーキテクチャでは、Streaming MultiProcessor(SM)と呼ばれるCUには128個のCUDAコアがあり、一般にこれをPEと呼ぶのかもしれません。
しかしSMにはこの他にLoad/Store Unit(LD)が32個、Special Function Unit(SFU、三角・指数関数の計算等に特化)が32個あります。ワークアイテムとPEのマッピングには、これらも含まなくてはなりません。特定の演算器だけを選んでPEの数とし、その数をワークアイテム数とすると、実際の処理との乖離・誤差が発生します。
ここで重要な点は、ワークアイテムの数がアラインされているほうが、PEがフル稼働する可能性が高くなることです。このためパフォーマンスをチューニングする際には、できるだけ正確なワークアイテム数が必要となります。しかしOpenCLにはPEの情報を取得するメカニズムが存在しません。
そのためワークアイテム数の推計を、ベンチマークやプロファイラー等を使って行なう必要があります。このやり方は率直に言えば、いい加減です。ですが開発者にとってPEがいかにマッピングされるかという抽象的な思考では解決できない、チューニングの手間暇が必要な泥臭い部分です。
IntelのHD Graphics GPUでは、CUのことをExecution Unitと呼びます。下記の図を見て頂くと、デバイス内には2つのサブスライスがあり、サブスライス内には複数のEUがあります。
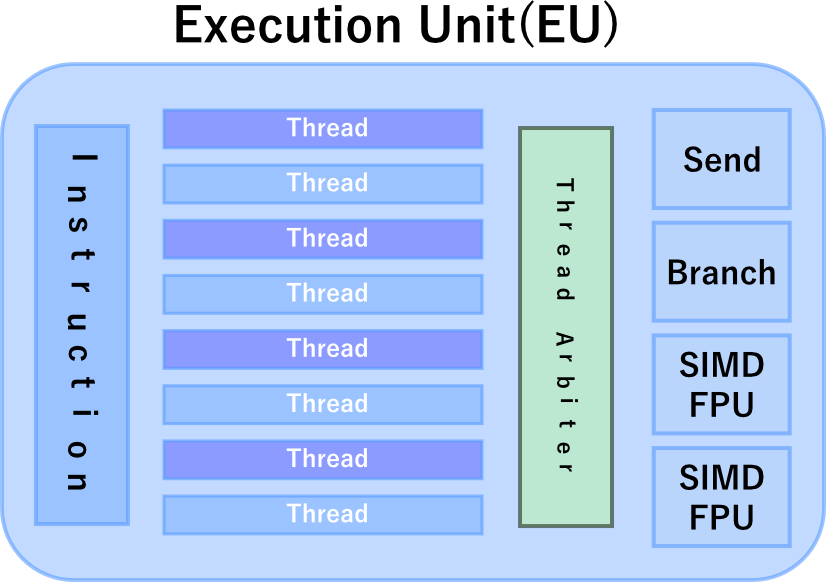
NVIDIAやAMDの外付けグラフィックボード、IntelのHD Graphics内蔵ボード(iGPU)には、これに対応する処理ユニットが存在します。
IntelはExecution Unit(EU)がCU、Processing ElementはEU内のSIMDチャンネルに相当するものとしています。
Intel HD 4000のExecution UnitをCUとしワークグループを割り当てるとすると、少なくとも16個のワークグループを設定したコマンドを作成しないと、EUは待機状態となります。
NVIDIAのCompute UnitはStreaming MultiProcessor(SM)と呼びます。分かりやすくするためにCUDAコアと呼ぶこともあります。下表は幅広く利用されているGTX980とGTX970のスペックです。
デフォルトのメモリーがGDDR5の4GBですので、IntelのHD Graphicsのグローバルメモリーよりも高速なデータ処理が行なえます。
項目 | GTX 980 | GTX 970 |
CUDA Cores | 2048 | 1664 |
Base Clock (MHz) | 1126 | 1050 |
Boost Clock (MHz) | 1216 | 1178 |
Texture Fill Rate (GigaTexels/sec) | 144 | 109 |
Memory Clock | 7.0 Gbps | 7.0 Gbps |
Standard Memory Config | 4 GB | 4 GB |
Memory Interface | GDDR5 | GDDR5 |
Memory Interface Width | 256-bit | 256-bit |
Memory Bandwidth (GB/sec) | 224 | 224 |
NVIDIAではリリースしたチップセットのアーキテクチャによって、CUに割り当てれる共有メモリーのサイズが異なります。アーキテクチャにはKepler、Maxwell、Pascal(2016年リリース予定)といったものがあります。
GTX970およびGTX980ではGM204(第2世代Maxwellのコードネーム、第1世代はGM107)アーキテクチャを採用しています。GM204はGraphics Processing Clusters (GPCs)、Streaming Multiprocessors (SMs)、メモリコントローラーからなり、GTX980の構成は以下のようになります。
- 4個のGPC
- 16個のMaxwell SM(SMM)
- 4個のメモリコントローラ
1個のGPCには4個のSMMとラスターエンジンが付いています。各SMMには128個のCUDAコア(Streaming Processor)が付いています。ちなみにKeplerアーキテクチャでは、SMではなく、SMXと呼ばれていましたが、OpenCLの用語上はCompute Unitと同義です。つまりGTX980は(16*128=)2048個のCUDAコアがあります。
AMDはGCN(Graphics Core Next)規格をGPUデバイスに採用しています。GCNではGCN Compute Unitと、OpenCLと同名を使います。
GCNは旧世代アーキテクチャのVLIW (Very Long Instruction Word) に代わり、4つの独立したSIMDを持ちます。SIMDエンジンはグループ分けした64個のワークアイテム(スレッド)を発行することができ、このグループをwavefrontと呼びます。
各SIMDは、16個のワークアイテムを並列に処理できます。各ワークアイテムは別のwavefrontでも処理が可能となり、柔軟なSIMDチャンネルのスケジューリングを可能とさせます。
表2.12 GCNとVLIW4の比較
| VLIW4 SIMD | GCN QUAD SIMD |
|---|---|
64 単精度 Mad(Multiply and Add) | 64 単精度 Mad(Multiply and Add) |
1 VLIW x 4 ALU ops | 4 SIMD x 1 ALU ops |
各SIMDは40-bitのプログラムカウンターと、10個のwavefrontで用いる命令バッファーを持ちます。つまり、各CUは4つのSIMD、つまり40個のwavefrontを異なるワークグループやカーネルから活用できます。32 x CUをもつAMD Radeon HD 7970であれば、最大81,920のワークアイテムを同時に処理が可能となります。
HBMを搭載して省電力化を実現したFury X等のGPUもGCNアーキテクチャを採用しており、OpenCLで開発を行なう場合には、OpenCLのバージョンを除いては特に変わることはありません。
GCNには1.0/1.1/1.2のバージョンがあります。もし詳細の仕様を知りたい場合は、お使いのAMD GPUがどのバージョンをサポートしている確認してから、「GCN Architecture Whitepaper」等のドキュメントを参照するとよいでしょう。